
HF 01
待完成
- 示例详解
Why
全面拥抱Transformer:NLP三大特征抽取器(CNN/RNN/TF)中,近两年新欢Transformer明显会很快成为NLP里担当大任的最主流的特征抽取器。
像Wordvec出现之后一样,在人工智能领域种各种目标皆可向量化,也就是我们经常听到的“万物皆可Embedding”。而Transformer模型和Bert模型的出现,更是NLP领域划时代的产物:将transformer和双向语言模型进行融合,便得到NLP划时代的,也是当下在各自NLP下流任务中获得state-of-the-art的模型-BERT
BERT起源于预训练的上下文表示学习,与之前的模型不同,BERT是一种深度双向的、无监督的语言表示,且仅使用纯文本语料库进行预训练的模型。上下文无关模型(如word2vec或GloVe)为词汇表中的每个单词生成一个词向量表示,因此容易出现单词的歧义问题。BERT考虑到单词出现时的上下文。例如,词“水分”的word2vec词向量在“植物需要吸收水分”和“财务报表里有水分”是相同的,但BERT根据上下文的不同提供不同的词向量,词向量与句子表达的句意有关。
Embedding:
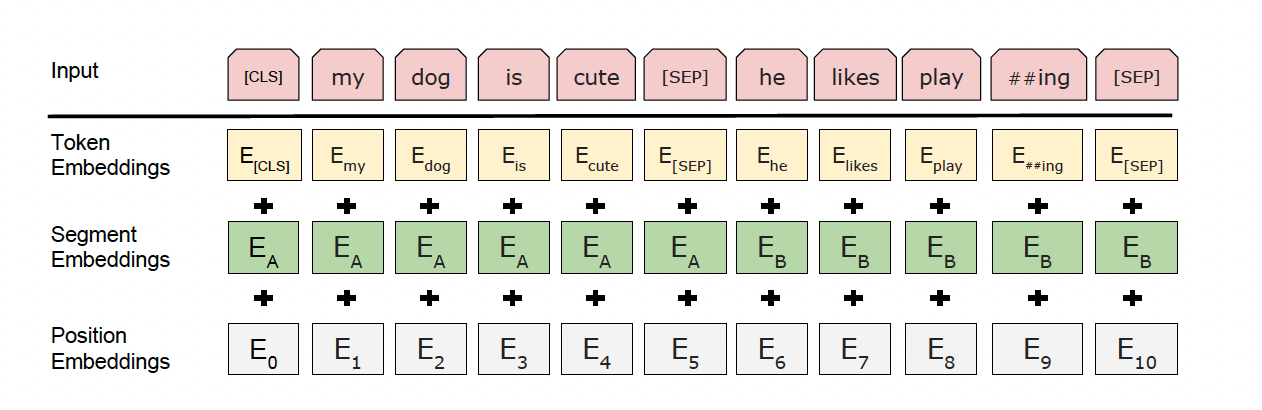
- 首先类似 word2vec 的 token化,再进行片段标记( segment ),最后 ids 的位置编码( position )
- 编码后一个 ’词‘ 有三个信息,token、段落位置信息、绝对位置信息( id: 1、2、3…)
Embedding解决的问题:
- 首先是之前用的 One-Hot Key,高维度,离散的,低信息密度的储存形式
- 其次是更好的 Contextual Similarity,上下文相关相似性。
Preview Api
前置查看:
1 | from transformers import BertTokenizer |
函数调用:
字典大小,token化,ids化
1 | vocab = tokenizer.vocab |
Mask模型的使用
1 | from transformers import BertForMaskedLM |
輸入 tokens : [‘[CLS]’, ‘等’, ‘到’, ‘潮’, ‘水’, ‘[MASK]’, ‘了’, ‘,’, ‘就’, ‘知’] …
Top 1 (65%):[‘[CLS]’, ‘等’, ‘到’, ‘潮’, ‘水’, ‘来’, ‘了’, ‘,’, ‘就’, ‘知’] …
Top 2 ( 4%):[‘[CLS]’, ‘等’, ‘到’, ‘潮’, ‘水’, ‘过’, ‘了’, ‘,’, ‘就’, ‘知’] …
Top 3 ( 4%):[‘[CLS]’, ‘等’, ‘到’, ‘潮’, ‘水’, ‘干’, ‘了’, ‘,’, ‘就’, ‘知’] …
可视化模型: bertviz
Pandas预处理文本
- 多使用自定义函数
- nltk库的stopwords
- textblob库的拼写检查、词干抽取、词性还原等
文本数据的基本体征提取
词汇数量
字符数量
平均字长
停用词数量
特殊字符数量
数字数量
大写字母数量
文本数据的基本预处理
- 小写转换
- 去除标点符号
- 去除停用词
- 去除频现词
- 去除稀疏词
- 拼写校正
- 分词(tokenization)
- 词干提取(stemming)
- 词形还原(lemmatization)



