
Attention机制
待完成
- 失效图片处理
传统Seq2Seq

左侧为 input 将句子一个一个投入到 encoder 中,
encoder整个处理其相关性得到 context,吐给 decoder,
decoder 进行一个一个解码输出,得到整个翻译后的句子。
Attention
An attention model differs from a classic sequence-to-sequence model in two main ways:
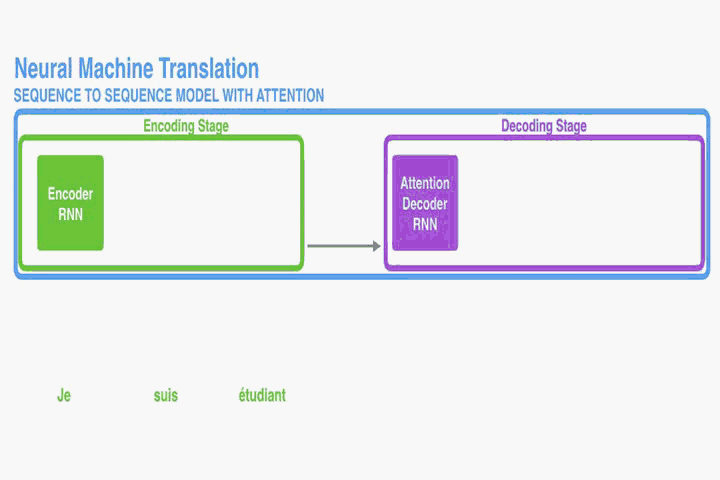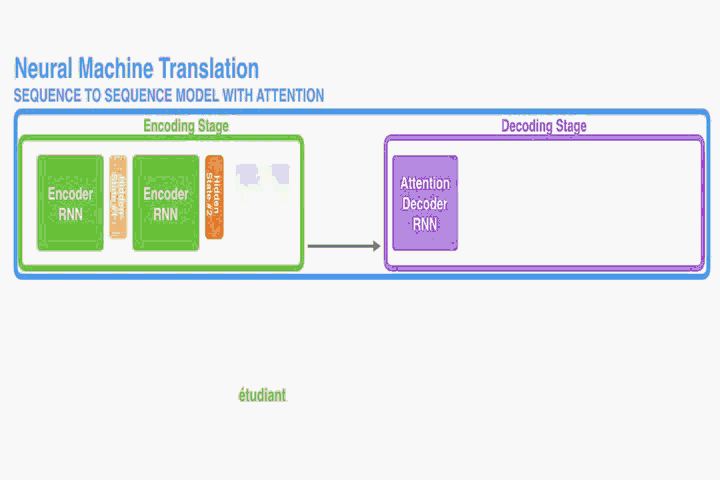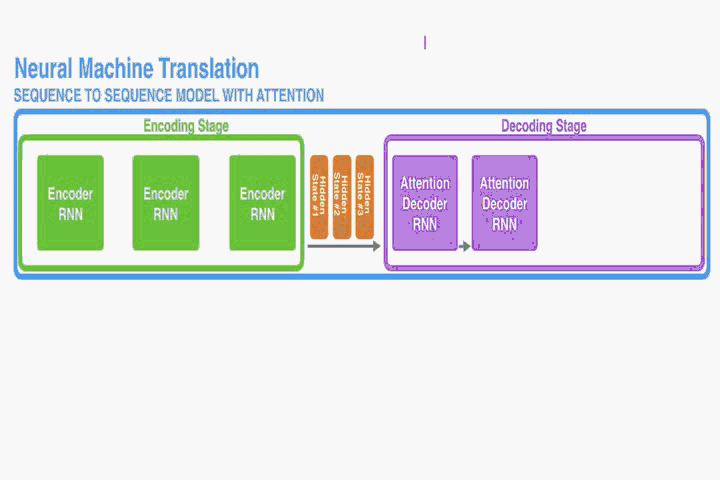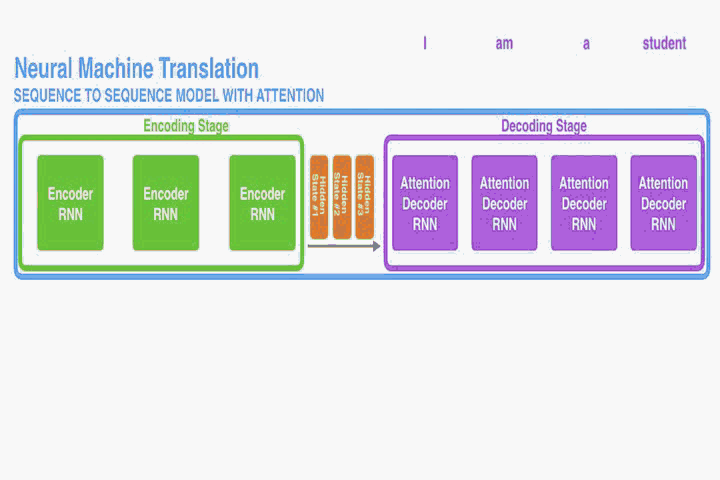
- First, the encoder passes a lot more data to the decoder. Instead of passing the last hidden state of the encoding stage, the encoder passes all the hidden states to the decoder:
注意力机制将产生的隐藏层信息(时间步骤信息),全部保留,一次性传给 Decoder。
Second, an attention decoder does an extra step before producing its output. In order to focus on the parts of the input that are relevant to this decoding time step, the decoder does the following:
Look at the set of encoder hidden states it received – each encoder hidden state is most associated with a certain word in the input sentence
Give each hidden state a score (let’s ignore how the scoring is done for now)
Multiply each hidden state by its softmaxed score, thus amplifying hidden states with high scores, and drowning out hidden states with low scores
decoder 将 encoder 输入的隐藏层的 vector 进行打分得到一个分数vector,
将分数 vector 做 softmax,得到一个权重 vector,
将权重 vector 与隐藏层 vector 相乘得到 注意力 vector,
最后把注意力 vector 进行相加就完成了。

- 注意: 将 encoder 的隐藏层信息传入 decoder之后,decoder 每一步都将使用其传入的隐藏层信息做 attention。
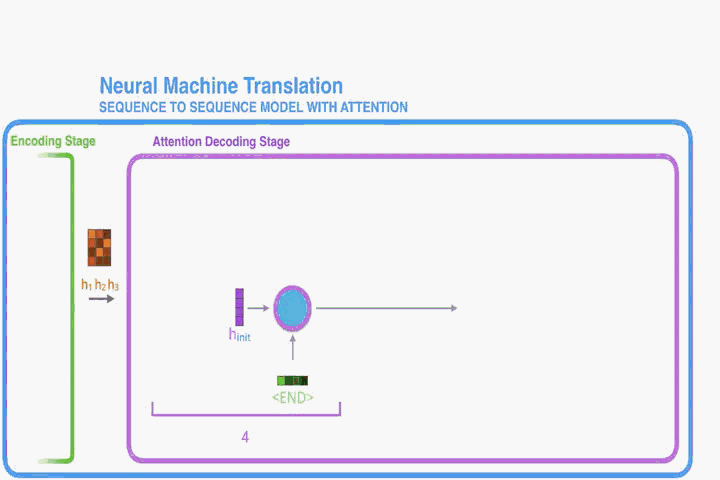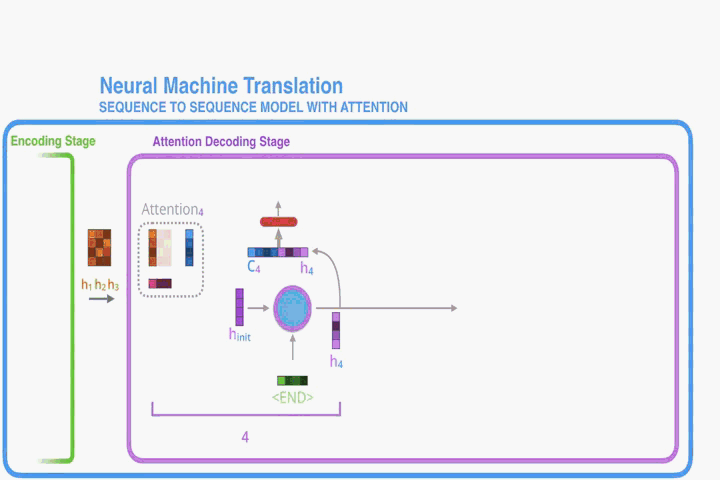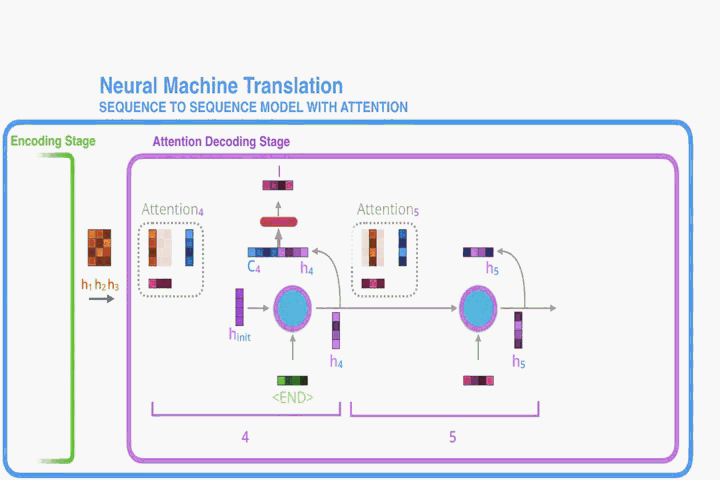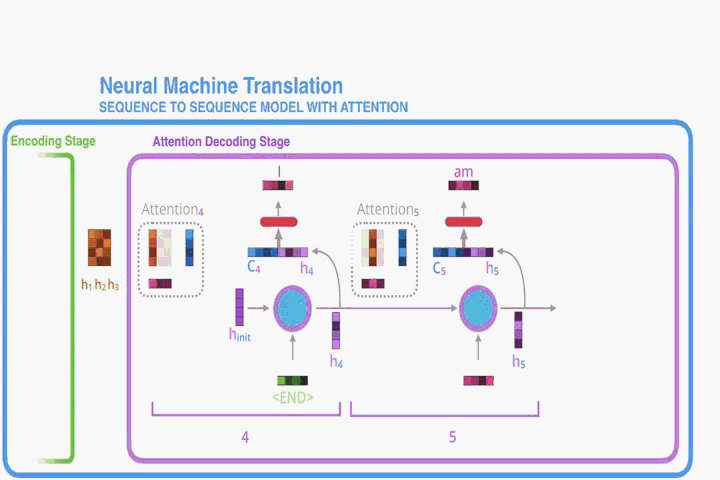
由上图可以看到,输出时 Attention 机制就是将注意力放在分数最高的向量上,所以,称之为’注意力机制’