
CV 01 CNN MNIST识别
前言
本文将通过CNN 让计算机识别MNIST数据集中的手写数字 以此来介绍Pytorch的基本使用方法:
- Pytorch中的数据类型——tensor
- Pytorch中的数据集、数据加载器——Dataset、DataLoader
- Pytorch中的基础类模型——torch.nn.Module
以及程序设计上的一些小技巧。
1. tensor
1.1 概念
tensor一词译为张量,一般我们所接触的矩阵是二维的,称为二阶张量、向量称为一阶张量、标量称为零阶张量。接下来我们通过Numpy库了解一下张量。(这里并非数学上严格的定义,感性理解一下即可)
1.1.1 二阶张量 矩阵
1 | # 首先我们举一个三行八列的矩阵 |
上面我们创建了两个矩阵a为三行八列,b为八行三列,两者做点积得到一个三行三列的矩阵。
我们拉到列表的角度解释这个矩阵,我们将所有数据都包含在一个大列表之内,大列表里有三个小列表,每个列表内有八个元素,
即三个小列表代表三行,每个列表的八个元素代表八个维度。
这里举个小栗子帮助理解一下维度:
我们在三年级二班给各位同学做信息登记,每个人所需要填写【姓名、年龄、身高、体重】四项内容,我们把每个人的信息记为一条数据,那么我们就可以说这条数据有四个特征,它的维度为四。
通常来讲我们把特征记为feature,称这条数据有四个特征。
现在整个班级的信息都填写好了应该是如何的形状,我们假设有32个人:
【【张三、7、130、 70】
【李四、7、131、 71】
。。。
【李小明、7、129、70】】 如何我们得到一个32行4列的矩阵,记为(32,4)
接下来我们把视角拉倒整个三年级,我们假设有7个班级:
那么我们得到的数据维度应该是(7,32,4),表示我们有7个班级的数据,每个班级的数据维度(32,4)。
此后我们都称这个“班级为batch“ ,至此我们从二维的矩阵上升到三维的张量。
1.1.2 张量
下面我们将介绍常用的张量形式
1 | # 首先介绍下一张图片通常的数据格式,我们使用Numpy来伪造一下数据 |
上面就是一张图片**W(width)为28,H(heigh)**为28,有RGB三个通道,batch为1的图片(这个batch里面只有一张图片)的数据表示形式。
当然上面的数据太过复杂,我们以下面W和H都为4的数据继续讲解一下各个数据的意义。
1 | np.random.randn(1,3,4,4) |
一号位batch=1表示只有一张图片
- 若batch=3,我们下面降到的模型依次取本批次内【0】号(3,4,4)、【1】(3,4,4)、【2】(3,4,4)进行处理
二号位Channel=3 表示有三个通道分别是RGB
- 如上面 0.43748082….0.00401234,就表示在R通道内,这张图片的颜色数据
- G和B通道同理,让三者叠加就可以表示颜色的明暗,从而勾勒画面,渲染颜色
最后的两位就表示长宽,每个元素表示像素点的明暗程度。如R通道的第一个元素0.43748082就表示这个像素点有多红
(红也有程度对吧)
1.2 Pytorch中tensor的API
Pytorch中tensor号称是跟Numpy及其相似的操作方式,有Numpy的学习基础的话几乎不用付出学习成本来适应tensor。但是实际情况就经常出现各种警告。无论如何,tensor可以享受到GPU的加速运算,总的来说也够友好,下面我们将介绍其常用的API
首先是随机函数,基本跟Numpy是一样的。
1 | rand_tensor = torch.rand(shape) |
接下来介绍tensor对象的一些属性,其中device默认就是使用cpu,表示我们数据在cpu上。
1 | tensor = torch.rand(3,4) |
torch.cat也是一个常用的函数,用来链接数据。
下面以第一行为例,cat函数将[0.8165, 0.1909, 0.6631, 0.3062]与[0.8165, 0.1909, 0.6631, 0.3062]、[0.8165, 0.1909, 0.6631, 0.3062,]连接,这是因为dim=1表示在第一维度,其视角内的可操作单位为0.8165, 0.1909, 0.6631, 0.3062这些元素,dim=0则可操作的基本单位为tensor(这里的tensor表示上面的三行四列的实例张量)
1 | torch.cat([tensor, tensor, tensor], dim=1) |
另外介绍一下常用的类型转换
1 | t = torch.rand(3,4) |
最后最常用的就是下面两句
1 | data = list(range(1,10)) |
2. Dataset DataLoader
都说数据科学家一般的时间都花在数据处理上,一点不假。前面花了这么大篇幅讲价tensor,接下来我们将介绍Pytorch中存储数据的
Dataset和数据加载器DataLoader
2.1 你的数据类
虽然我们使用的MNIST数据集已经可以直接通过Pytorch的API调用,如下
from torchvision import datasets
datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
root表示存储或者加载数据的路径
train表示是否只加载训练部分的数据集,不设定默认加载全部数据集
download字面意思
transform指代这批数据使用什么转换形式,一般来说是一种数据增强方式,以后会专门介绍
我们还是来具体解释下通常要自定义使用的dataset。
定义符合你要求的数据集有三步必须操作:
- 定义你自己的数据集类并继承自
torch.utils.data.Dataset - 需要包含
__len__方法返回长度 - 需要包含
__getitem__方法,按照下标取得数据
以上配置也都是为了配合DataLoader的使用,下面我们定义一个dataset类
1 | from torch.utils.data import Dataset |
上面我们引入kaggle著名的泰坦尼克号幸存者预测比赛使用的数据集,其中x_data获得的是前八百行乘客的信息,y_data记录的就是是否存活。
一般来说我们也将数据集分为train和valid两部分,因为最后我们需要预测的数据集并不会有是否存活的标签,所以通过训练模型参数以拟合train部分的数据,以valid为本次训练的结果导向以修正模型参数,最终预测,就是我们的目的。
如上面所示,Python中的语句就是这么简洁明了,我们在初始部分读取数据集,然后根据传入的flag决定是处理train还是valid的部分数据,最后我们赋予这个类像列表那样的获取下标和切片能力(__getitem__方法)、以及返回长度的能力(__len__方法)
2.2 数据加载器
Pytorch的数据加载器DataLoader简单易用,下面介绍它部分常用参数。
1 | train_dataset = TitanicDataSets(flag="train") |
- dataset 表示它所处理的数据,一般是你定义的dataset类,或者具有下标取值,和返回长度的数据类型也可以
- batch_size 表示一词传给模型多少条数据
- shuffle 表示是否打乱
- num_workers 表示使用你cpu的几个核进行读取
可以使用下面的语句查看dataloader返回给你的数据形状
1 | samples = next(iter(train_loader)) |
3. 模型
对于模型,以我的理解,数据虽然是死的,但是理解它的方式是活的;模型是活的,但是组合它的方式并没有那么灵活。这里之所以说是组合,说点题外话,是因为如今预训练模型大行其道,大模型在各个任务上不断刷新纪录(SOTA),小型机构很难有力量去训练这种大模型,于是在大模型上修修改改以适应下游任务的方式,只能使用这种像是Transformer的方式不断变形组合,总感觉缺了点活力。(奠定Pre-train的Bert就是在Transformer基础上提出来的)。
3.1 模型定义
下面开始定义我们的CNN模型
1 | class Net(torch.nn.Module): |
- 初始化部分就是定义这个模型的各种方法
- forward向前传播,应用初始化部分定义的函数
因为MNIST数据集是黑白图片所以只有一个通道(以灰度grey刻画图像即可)
3.2 模型功能细节
torch.nn.Conv2d即convolution(卷积层)
第一个参数表示进入卷积层数据的channel数
第二个参数表示完成卷积后数据的channel数
padding=1 即在图形周围填充一圈为0的数据(一般来说是有些图形在某些情况下不padding将会取不到原本边界上的值)
kernel_size表示卷积核大小(3,3),如图所示(5,5)的图形padding之后变为(7,7),其经过卷积核映射成(3,3)的形状
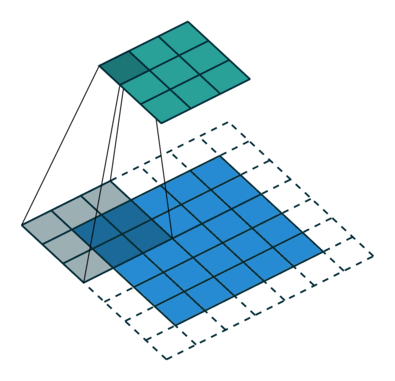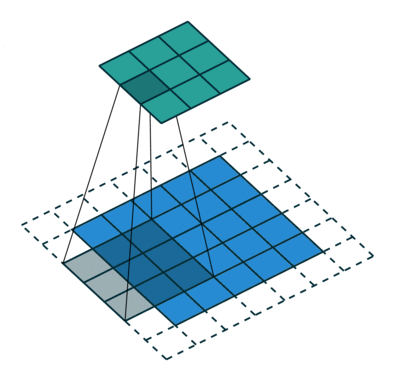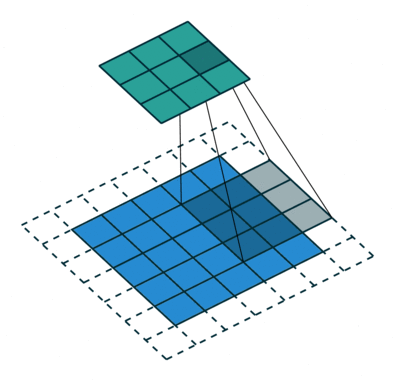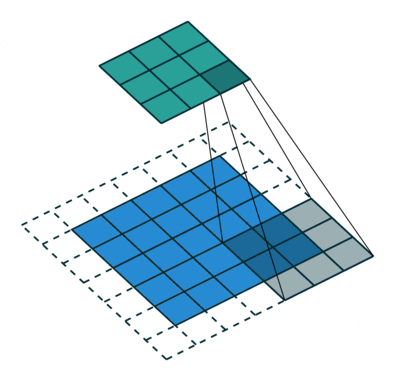
卷积核进行的操作是elementwise multiplication,就是元素与核上对应元素相乘之后加起来就可以了
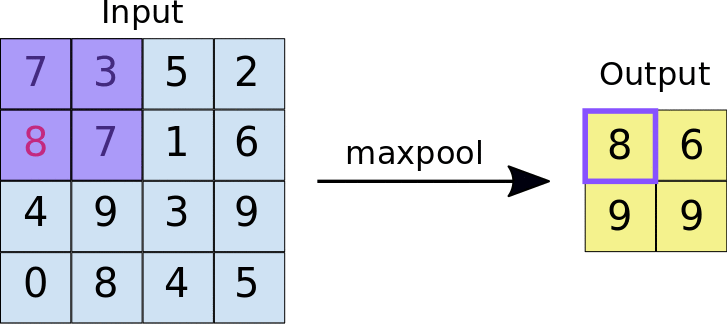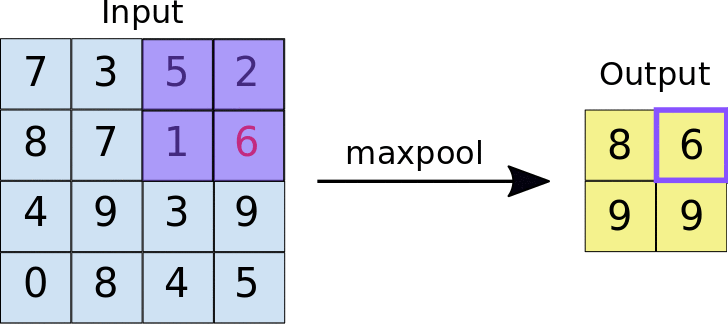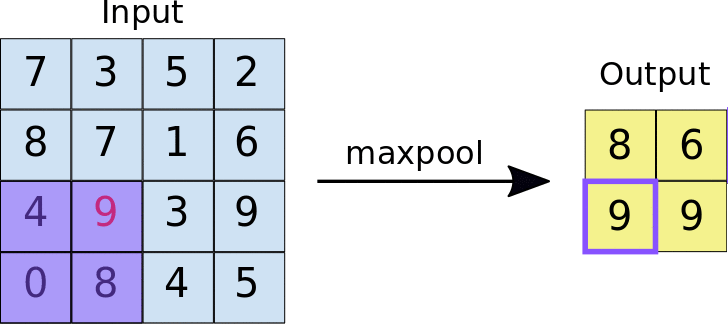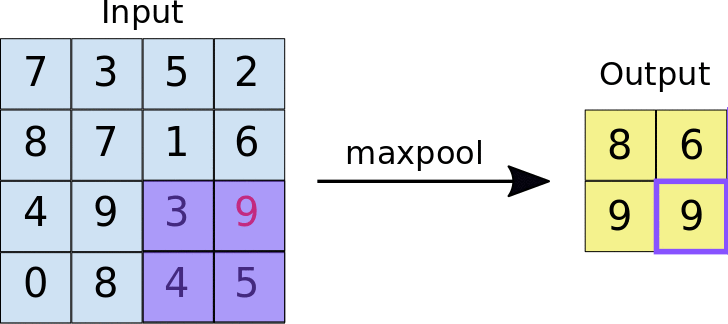
torch.nn.MaxPool2d
也就是在一个设定的核的窗口内取最大值
注意maxpool就是为了取得此区域最大值作为特征输出给下一层的所以不会有overlap的地方
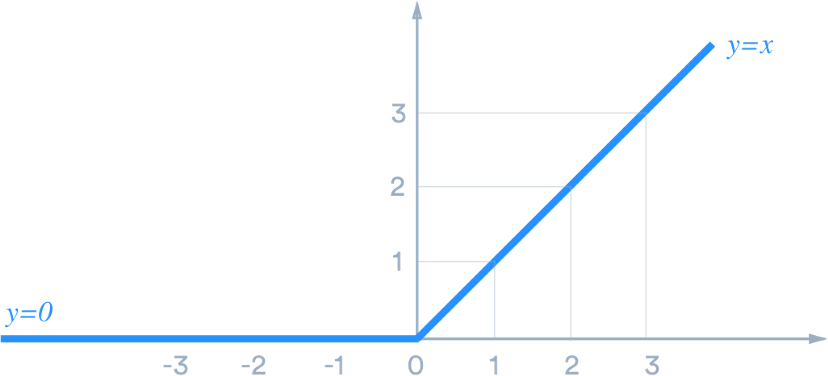
激活函数relu
直接上图,置于sigma函数、softmax函数、tanh函数之后会开文讲
torch.nn.Linear
就是全连接层。
对于经过卷积、池化、激活的数据,维度为(batch_size, b, c, d),
我们将其压缩为(batch_size, n) 最后送给全连接层做n到10的映射,最后变为(batch_size, 10),以最大数的下标作为我们模型的预测结果
1 | # 如batch_size = 2 |
4. 训练
4.1 一般流程
首先将模型实例化,并引入损失函数、优化器和设备。(关于损失函数和优化器之后也会开文讲)
1 | model = Net() |
加载数据,这里函数名都是见名知意,很好理解
1 | batch_size = 64 |
下面定义训练循环
1 | def train(epoch): |
以上模型准确率在98%
4.2 看看准不准
以下内容使用jupyter notebook查看
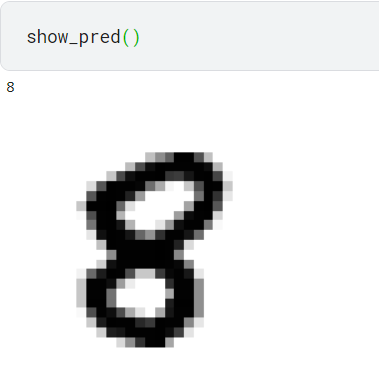
单个查看(train_loader就是上面流程中定义的)
1 | import matplotlib.pyplot as plt |
批量查看(train_loader就是上面流程中定义的)
1 | import matplotlib.pyplot as plt |
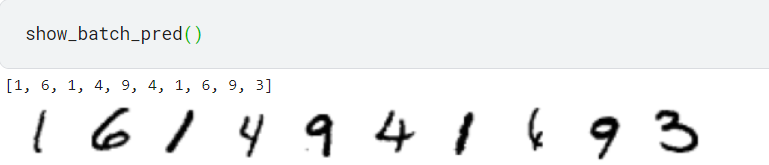
可以看到还是错了一个的,倒数第三应该是4 (要不就是我看错了)
总结
- 下面我们来总结一下训练一个模型的pipeline,我认为总结让我们的pipeline获得一定的泛化能力
1 | import torch |
回顾整个流程: 准备数据—> 定义模型—> 训练循环设计—> 超参数—> 训练并分析结果。各个环节细节的设计请各位参照Pytoch官方文档研究
以上就是整个数据到模型到结果的流程,下节我们将介绍VGG、ResNet50等预训练模型
