
Transformer & Self-Attention
待完成
- 失效图片处理
李沐老师 48分钟讲解 encoder-decoder中(KV–Q)的运算:
KQ相乘就是单个q对所有k的相似度作为attention score(给这个K值多少注意力),与单个v做加权和(权值来自KQ)
再通过注意力分数与V向量相乘,得到每个V应该多大的缩放, 进行相加后就得到了最终V应该是什么样子了
李沐老师 56分 对multi-head输出和linear层相较于RNN的讲解:
词向量经过Attention层抓取全局信息,汇聚之后,在每个点上都有了所需要的信息
(权重不同,每个输出的向量的重点在不同的position编码位置上),因此只需要做linear transformation。
bert中transformer参数计算:
embedding: vocab_size=30522, max_position_embeddings=512, token_type_embeddings=2(就进行两句分别标记,多了截断)
(30522+512+2)*768 = 23835648 (23M)
self-attention: 768/12 = 64 (多头每头分64维度的向量) ,64*768(每个64映射回768),QKV三个矩阵,
最后一层 786(64 *12的拼接)->768的线性变换
(768/12 * 768 3 ) * 12 + (768768) = 2359296
经过12个transformer
2359296*12 = 28311552 (28M)
feedfoward: 自注意力层之后 分别在 encoder 和 decoder 中有个一个全连接层
维度从 768->4*768_768->768
(768*4 * 768 )*2 = 4718592
(768*4 * 768 )*2 * 12 = 56623104 (56M)
layernorm: 有伽马和贝塔两个参数,embedding层(768 * 2),12层的self-attention,
768 * 2 + 768 * 2 * 2 * 12 = 38400
总计: 23835648+28311552+56623104+38400 = 108808704 (108M)
每一层的参数为: 多头注意力的参数 + 拼接线性变换的参数 + feed-forward的参数 + layer-norm的参数
768 * 768 / 12 * 3 * 12 + 768 * 768 + 768 * 3072 * 2 + 768 * 2 * 2 = 7080960 (7M)
Encoder 编码阶段
Multi-head Attention
多头注意力机制将一个词向量留过八个 self-attention 头生成八个词向量 vector,
将八个词向量拼接,通过 fc 层进行 softmax 输出。
例如:
词向量为 (1,4) –>
经过 QKV 矩阵(系数) 得到 (1,3) 八个 (1,3)*8 –>
将输出拼接成 (8,3) 矩阵与全连接层的系数矩阵进行相乘再 softmax 确定最后输出的 词向量 –> (1,4)
注意 QKV矩阵怎么来的(attention分数),最后为什么要拼接,以及FC层的系数
qk相乘得到,词向量与其他词的attention分数( q1*(k1,k2,k3) )
多头注意力机制让一份词向量产生了多份答案,将每一份注意力机制的产物拼接,
获得了词向量在不同注意力矩阵运算后的分数,进行拼接后,softmax输出最注意的词,即是注意力机制。
多头注意力机制,将向量复制n份(n为多头头数),投影到如512/8 = 64的64维的低维空间,最后将每一层的输出结果
此处为八层,8*64=512 拼回512维的输出数据
由于Scale Dot Product 只是做乘法点积(向量变成qvk之后的attention运算),没什么参数,因此重点学习的参数在Multi-Head的线性变换中,
即将 64*8的八份数据线性变换的下文中的W0,给模型八次机会希望能够学到什么,最后在拼接回来。==
注意力机制流程:
q –> 查询向量
set( k,v) k –>关键字 v—-> 值
如果 q对k的相似度很高,则输出v的概率也变高

’多头’注意力机制
请注意并推演其词向量维度与系数矩阵带的行数
![]()
Scale Dot Product

step1
QK做点积,则输出每一行,是q与所有k的相乘相加结果,
α1 = (q11k11+q12k21+q13k31 , q11k12+q12k22+q13k32 )
α2同理。
step2
所以得到了query1对所有key的相似度,最后每一行做个softmax进行概率分布。
除以根号dk是为了平滑梯度,具体来说:当概率趋近于1的时候softmax函数的梯度很小,除以dk让数值接近函数中部,梯度会比较陡峭
step3
将第二步的结果与V相乘得到最后的输出
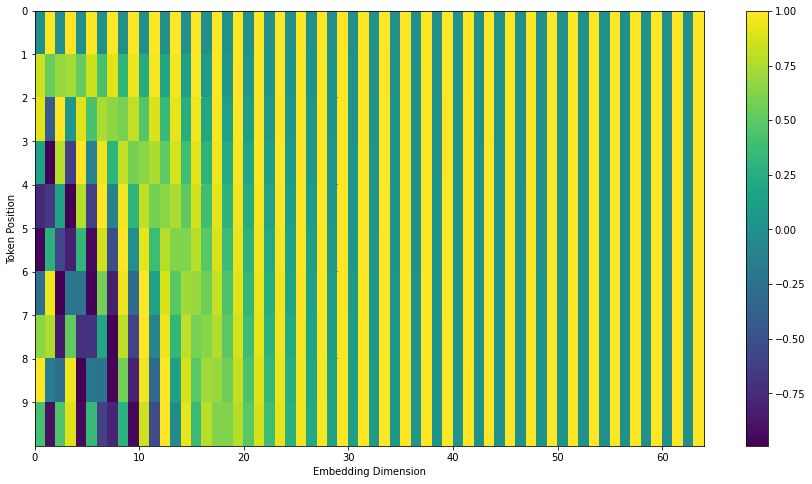
Position Embedding
位置编码是 将embedding好的词向量加上 position embedding vector 将信息融合,在注意力机制中进行计算。
(原文是使用sin cos将词向量份两部分进行编码, 本文中将交替使用sin cos,即单数sin 双数cos)
位置嵌入编码,主要是为了编辑定位词向量的位置以及词向量间的相对距离
pos为 词的种类数,为行标号
i 为特征维度
len(pos) * len(i) 表示为一position embedding 矩阵, 每一行为词的位置信息,每一列表示在特征上偏置,
将位置信息 融入 词向量信息 使词获得 时间上的相对信息

Residual 细节
![]()
Decoder 解码阶段
Mask Multi-head
与encoder不同的是,解码器在工作时会引入 Mask Multi-head 机制,将右侧的词盖住(设为负无穷或者别的)。
具体来说:
encoder 将生成的K和V矩阵传入 decoder 的 self-attention 模块中,而 decoder 将 mask 后的Q矩阵与其做attention。
mask做的事情


![]()
解码还是得一个个来的
时间维度
在时间序列的情况下,词向量表示为,t1时刻的vector,t2时刻的vector….
mask做的事情就是将后面(右边)的 tn个时刻都屏蔽掉,
而Qmatrix的形成 将vector含有了其之后词的信息(共享了系数矩阵),所以将其右边屏蔽。
则剔除了后面词的信息,从而不进行考虑。
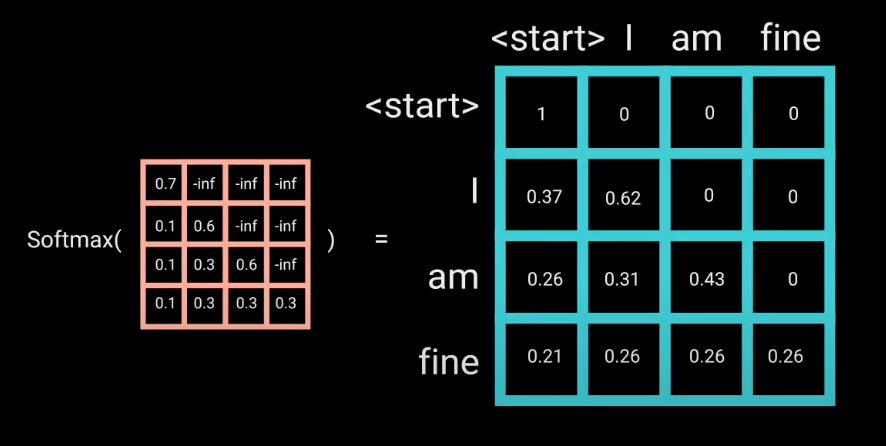
Mask 细节
mask就是为了阻止词知道后面的信息,具体来说就是QKV矩阵还相乘,但是引入-inf来阻止右边(后面的信息汇聚)

第一次点积:将Q和K矩阵相乘得到attention分数,
将右上角置零就会得到只含有本身信息和相对位置之前(左边)的信息,
且第二次点积: Mask(QK)与V相乘由下三角矩阵的性质,


注: mask去负无穷是因为 SoftMax中 e的指数形式只有在负无穷才为零,
这样相乘数据不会有一点影响,取其他值,都会影响softmax

总结
- 特别注意理解 attention机制将词向量之间的联系, attention分数
- embedding方式为 词向量+位置编码向量
- 引入了 Residual
- encoder-decoder层的传入为KV矩阵,decoder生成Q矩阵
- Mask方式
